AI copilots are increasingly being integrated with software to help users get more done with less effort. As AI copilots in SaaS become more common, it's important to understand how to build and deploy them effectively.
In this post, we'll dive into the technical details of building an AI copilot that can perform tasks on behalf of users in addition to sending messages. We'll use the OpenAI API as our AI model, but the principles should apply to any large language model (LLM).
The Easy Way: Use a Copilot Builder
If you're looking to build an AI copilot for your software, the easiest way to get started is to use a copilot builder like Rehance. You'll be able to side-step all of the complexities around fiddling with models, teaching them how to execute code or perform tasks, and figuring out the optimal AI copilot design to use.
With a copilot builder, you can get started in minutes, and have a working AI copilot on your website in a couple of hours. It's also a great way to test and validate the concept of an AI copilot in your product before investing in building a more custom solution.
The Hard Way: Allowing AI Copilots to Execute Code in Production
I know what you're thinking. LLMs must never touch any production code, APIs, or, God forbid, databases. I get it. LLMs can hallucinate and generate all sorts of incorrect or dangerous outputs.
But hear me out. There is a way to make this work, where we give AI copilots the power to execute code and make data transformations on behalf of users, without blowing everything up.
These learnings come from our experience working on an AI copilot platform. While our copilot isn't yet as robust as we describe in this post, we'll get there soon. This serves as, essentially, our roadmap.
Here's the summary:
- Create a high-level programming language or framework that you can compile and execute in production with safeguards.
- Pick an AI model that can generate great code in this language/framework.
- Provide a way for users to make requests in plain English, and have the model generate code to handle the user request.
- Allow users to review and approve the code before it runs (in plain text or visually, not the actual code).
Before we get into the details, a note on who this is for: you don't need to be an AI expert to understand this post, as most of the technical details around the 'AI' part are already abstracted away by the folks at OpenAI and other companies. This is a tactical guide for using those abstractions in practice to create AI copilots of real value to users.
Create a High-Level Language or Framework
This sounds more complicated than it is. You don't need to reinvent a programming language from scratch. I recommend taking an existing language—TypeScript is a great fit—and using it as a base. Then add guardrails to prevent the AI from generating code that could be dangerous.
The particular framework you choose can vary, but the key is to include in the prompt a
strictly-typed set of functions and data structures available to the LLM. These should be very
high-level to begin with (e.g., getUsers(), not database.query()) and should match your
software's features and APIs. They should be features that an individual user would be able to
access in your software.
Here's how you might get started prompting GPT4 to write valid Typescript in your app:
You are a Typescript expert, writing a simple program that can resolve a user's request. You cannot use any external libraries or APIs (including `fetch`, `axios`, etc.). You can only use the build-in data structures, such as arrays, objects, dates, and strings. You can use `if` statements, `for` loops, and `functions`. You cannot use `eval` or any other method that would allow you to execute arbitrary code. You must write code that is safe to run in a production environment.
Your code will be run in a sandboxed environment in [SoftwareName], a [SoftwareCategory] platform for [SoftwarePurpose]. As such, you have access to the following data structures and functions (provided to you in Typescript for convenience):
interface User {
id: string;
name: string;
email: string;
}
interface UserFilter {
id?: string;
email?: string;
}
type GetUsersType = (userFilter: UserFilter) => Promise<User[]>;
const getUsers: GetUsersType = async (userFilter) => {
// Implementation details are hidden from you.
// You can assume this function will return an array of User objects.
return [];
};
// Etc. Provide all the data structures and functions
// that the AI can use. Use getter functions instead
// of providing raw data to prevent the AI from
// accessing sensitive information.
Here is the user's input: "[UserInput]". Write a program that can resolve this request.
When we ran something like this, GPT4 spit out a program that was much too long, re-defining the existing types and attempting to write implementations of the functions we provided (instead of understanding that they were already implemented, and accessible to the AI). But we resolved that by adding some more constraints to the end of the prompt:
Do not include the provided types, or implement any functions that are already defined above. Only add the code necessary to execute the request, assuming the above functions and types are already available. Do not encapsulate your code in a function, do not provide example usage. You may assume your code will be executed in an async environment in which you can use `async/await`.
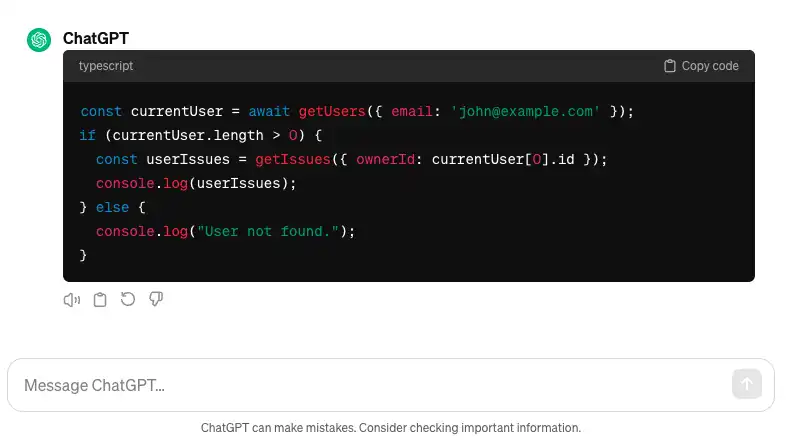
It's a rudimentary start, but you'd be surprised how much you can accomplish with an approach just like this. For example, here's the output of GPT4 when prompted with the above, using a project management software as an example, where the user wants to see all tasks assigned to them.
First, the types we provided in the prompt:
interface User {
id: string;
name: string;
email: string;
}
interface Issue {
ownerId: string;
title: string;
description: string;
tags: string[];
}
interface UserFilter {
email?: string;
id?: string;
}
interface IssueFilter {
ownerId?: string;
title?: string;
description?: string;
matchesAllTags?: string[];
matchesAnyTags?: string[];
}
type GetUsersType = (userFilter: UserFilter) => Promise<User[]>;
const getUsers: GetUsersType = async (userFilter) => {
// Implementation details are hidden from you.
// You can assume this function will return an array of User objects.
return [];
};
type GetIssuesType = (issueFilter: IssueFilter) => Promise<Issue[]>;
const getIssues: GetIssuesType = async (issueFilter) => {
// Implementation details are hidden from you.
// You can assume this function will return an array of Issue objects.
return [];
};
And the output:
const currentUser = await getUsers({ email: 'john@example.com' });
if (currentUser.length > 0) {
const userIssues = getIssues({ ownerId: currentUser[0].id });
console.log(userIssues);
} else {
console.log('User not found.');
}
That's pretty good! Simple code that uses the provided functions appropriately to resolve the user's request. We'll revisit this later to see how we can make it even better and handle more complex requests and edge cases, but first we need to deal with the compilation and execution part.
Compile and Execute in Production (Safely)
Assuming we've got a valid Typescript code snippet that we want to run, we need to ensure it doesn't do anything malicious and then execute it in production. This is perhaps the trickiest part, but it's manageable.
First of all, we need to get from Typescript to Javascript. That's easy enough, as typescript provides a transpileModule function that can do this for us. So we can take our Typescript file that we use in the LLM prompt, append the generated code to it, and transpile the whole thing to Javascript in memory. During this step, we should also catch any type or compile-time errors that the AI may have made, and re-prompt the AI to fix them or tell the user that we were unable to process their request.
That gets us to the point where we have a Javascript string that we can execute, and that is type-safe, making use of our functions/APIs appropriately. Now we just need to run the code in a sandbox. Again, we don't need to reinvent the wheel here. This problem has been solved before. One potential solution is safe-eval, or if you want to go lower level you can look into Isolate in the V8 API (used by Cloudflare Workers, for example). There's a node library for this called isolated-vm.
Sidebar: User Approval
Pivoting briefly from the technical side of this to AI Copilot UI/UX side, we need to allow users to review and approve the code before it runs, since the code may perform operations that the user didn't intend, like deleting some of their data.
The approach that should work for this is to first run the sandboxed code in a dry-run mode, where you don't actually execute the functions that would have side effects. Instead you record the function calls in chronological order and the arguments passed to them. Then you present this to the user in a human-readable format, and ask them to approve the execution. If they do, you run the sandboxed code again, but this time you actually execute the functions.
The tricky part here is that the user needs to understand what the code is doing, and why it's doing it. I won't get into too much detail here as it's more of a design question than a technical one, but suffice to say that this is a critical part of the system that needs to be designed well.
Here's our current (very rudimentary) approach to user approval. We plan to improve this significantly with time:
The user needs to know what's going on, and why, and be able to stop it or undo it if they don't like the result.
Interactivity
For a system like this to serve as a proper assistant that users can interact with, it needs to be able to have some back-and-forth with the user, asking for more information or clarification when needed, and communicating any issues with producing a valid result.
Since we've set up a programming framework for the assistant, this is actually quite easy. We
can simply define a function that the AI can use to send a message to the user and await their
input. You could even use console.log! Once the user replies with the necessary information, the
model can then generate the code to handle the request.
For example, say a user makes a request that's too vague for the system to interpret. It can generate the following output code:
sendUserMessage(
"I'm sorry, I don't understand your request. Could you please explain it in more detail?",
);
await waitForUserResponse();
On your end, you'd just hook up the sendUserMessage function to your messaging system, and
interpret waitForUserResponse to mean: take the user's reply, work it back into the prompt, and
run the new prompt through the model.

I will add that this flips the usual paradigm of LLMs a bit. Rather than generating text in natural language first, which may include code or anything else, instead we want to use a model that's always generating code, and work in natural language into function parameters or variables as it makes sense to do so. Code first, natural language as needed.
Optimize the System
The reason this approach is so powerful is that over time, LLMs that are optimized for writing code will get better and better. There is so much open source and publicly available code that even now, Copilot, CodeLlama, and similar models are able to generate code that is quite good.
By building a sandboxed environment and providing access to our own (high-level) APIs/functions, we also ensure that the assistant doesn't need to generate complex, low-level code that is potentially destructive. It only needs to do the basics—combining the existing features in the right ways to perform tasks for the users and automate their point-and-click flows.
Setting up a system like this means that to improve the system you basically just need to upgrade your LLMs and add more APIs/functions for them to use. Of course, once you've added all the features available to your software's users, all that's left is to keep upgrading to the latest models (and, of course, measuring the system's performance and user satisfaction).
Final Notes
This is a very high-level overview of how you might build an AI copilot that can execute code in production. The details will vary depending on your software and your users, but the strategy should be applicable to basically all user-facing software.
Remember, the goal is to draw a line in the sand between your software/APIs and the AI copilot's generated code, so that the assistant can only access the parts of your software that are appropriate, and in a strictly-typed, high-level, carefully controlled way.
What's Next For Us
We're building this out here at Rehance, and we're excited to see where it goes. This process is largely reusable from software to software, so we're hopeful that we can build a platform that makes it easy for any tech company to integrate and add an AI copilot to their software that's not just a gimmick, but a true assistant that can help users get things done.
We're also very intrigued to see how AI models, specifically those optimized for code generation, evolve in the coming months and years.